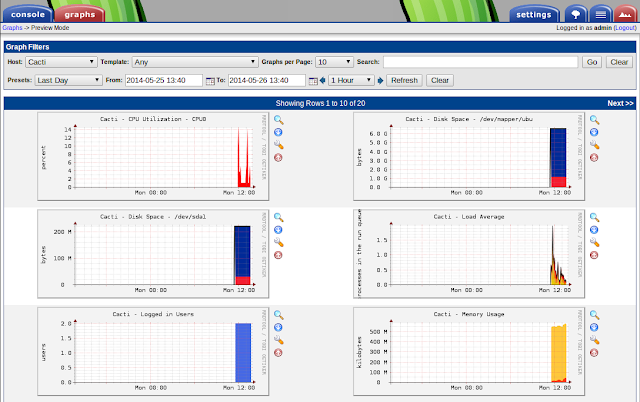
Zabbix เป็น Monitoring System อีกตัวหนึ่งที่น่าสนใจ ซึ่งมีคุณสมบัติหลากหลาย ไม่ว่าจะเป็น Performance Monitoring, Availability Report, Trigger, Event และ Graphs เป็นต้น Zabbix มี Template เสริมหลายตัว สามารถติดตั้งเพิ่มเติมได้ง่าย แถมยังสามารถตั้ง Trigger เพื่อส่งการแจ้งเตือนผ่านทาง E-Mail, IM และ SMS ได้อีกด้วย ความสามารถเยอะขนาดนี้ มาลองเล่นกันดูครับ
ติดตั้งบน Ubuntu 12.04 ทำได้ง่ายมากเพราะ Zabbix มี Repository ให้บริการไว้แล้ว แค่ติดตั้ง repo package ดังนี้
wget http://repo.zabbix.com/zabbix/2.2/ubuntu/pool/main/z/zabbix-release/zabbix-release_2.2-1+precise_all.deb
dpkg -i zabbix-release_2.2-1+precise_all.deb
apt-get update
ติดตั้ง Zabbix Server
apt-get install zabbix-server-mysql zabbix-frontend-php
แก้ date.timezone ใน /etc/apache2/conf.d/zabbix จากนั้น restart apache ดังนี้
service apache2 restart
ติด Zabbix Agent ในเครื่องที่ต้องการ Monitor
apt-get install zabbix-agent
ตั้งค่า Zabbix Server ให้ Agent โดยใช้คำสั่ง
dpkg-reconfigure zabbix-agent
ใส่ hostname หรือ ip address ของเครื่อง Zabbix Server ให้ถูกต้อง
เปิด browser ไปที่ http://YOUR-ZABBIX-SERVER/zabbix ตั้งค่าอีกนิดหน่อย


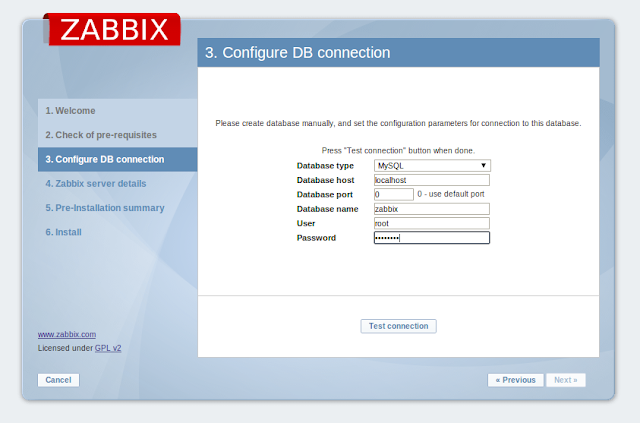
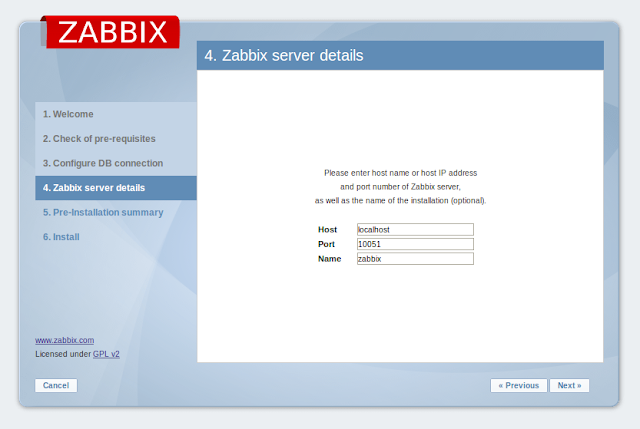
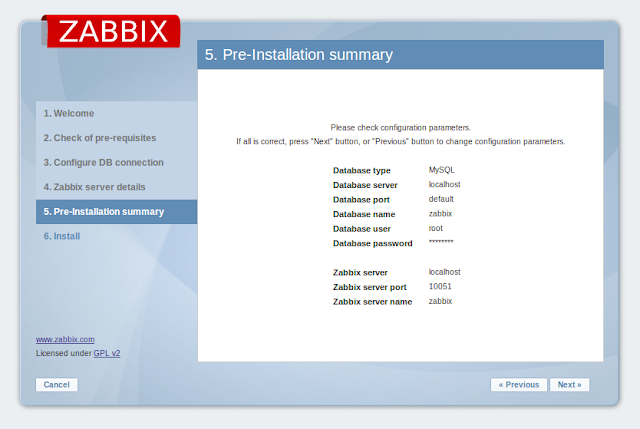

จากนั้นจะเข้าสู่หน้าจอ Login กรอก username = Admin และ password = zabbix
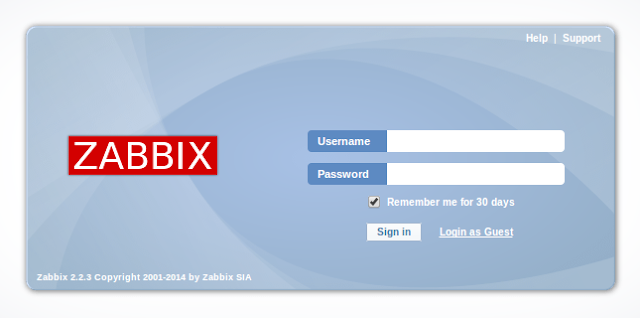
ก็จะเข้าหน้าหลักของ Zabbix แล้ว วิธีการใช้งานให้ติดตั้ง Zabbix Agent ไว้ที่เครื่องที่ต้องการ Monitor จากนั้น เพิ่ม Host ที่ Configuration > Hosts เลือก Create Host ใส่ข้อมูล Host ที่ต้องการ Monitor ลงไป
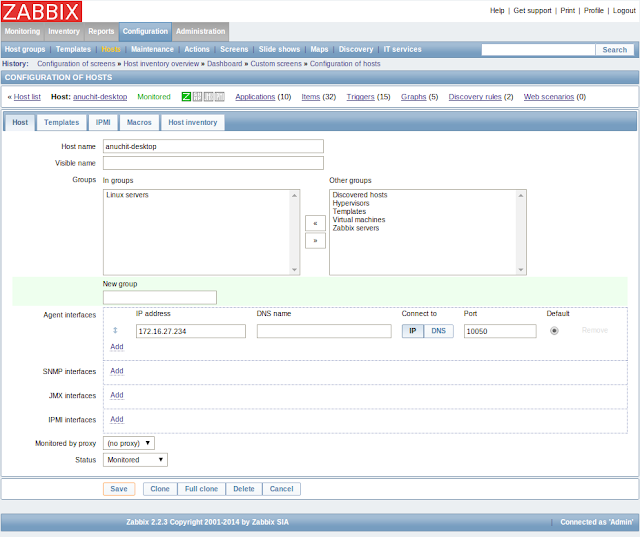
คลิกที่ Template เลือก Template ที่ต้องการ ตัวอย่างเช่น OS Linux ถ้าต้องการ Monitor Service เช่น HTTP, HTTPS, SMTP, SSH ก็สามารถเพิ่มเข้าไปได้
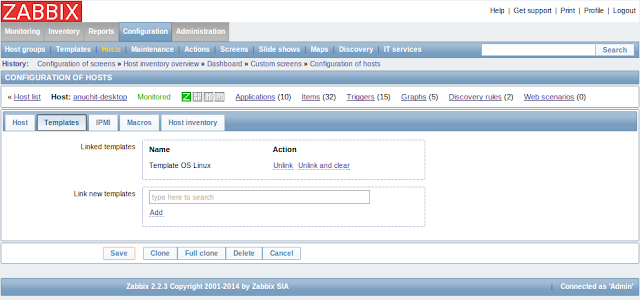
กด Save แล้ว เข้าไปดูที่ Monitoring > Lastest Data ว่ามีข้อมูลมาจาก Agent แล้วหรือยัง

เมื่อมีข้อมูลมาแล้วคุณสามารถดูข้อมูล System Status ผ่านหน้า Dashboard ได้ หรือจะดู Trigger หรือ Event ได้เช่นกัน